
如果你只想记住一句话:省 Token 的关键,不是把一句话压得更短,而是减少重复上下文、减少无效输出、减少不必要的高成本调用。
这篇文章不走“模板化教程”路线,只做三件事:
- 先告诉你,哪些方法最值得先做
- 再把
Caveman、graphify,以及前端场景里同样很值的Playwright CLI讲清楚 - 最后说清楚,这几个工具分别能给使用者带来什么增益
原文参考: 《最强 Claude 比黄金还贵,有人用省 token.skill 直降 65%,还有 10 个小妙招》 ↗
先看结论:最值得先做的是这 4 件事#
很多人一说“省 Token”,会先研究怎么把提示词写得更奇怪、更短,甚至用文言文、缩写或冷僻表达。那通常不是大头。
真正最值得优先做的,是下面 4 类动作。
- 管理上下文长度
这是最容易见效的一类优化。
- 编辑原消息,不要在后面一轮轮补丁式纠错
- 每 15 到 20 轮开新对话
- 多个相关问题尽量合并成一条消息
- 长背景资料不要反复上传
这些动作本质上都在做同一件事:减少“把旧信息再喂给模型一次”的次数。
- 控制输出长度
很多人的注意力都放在输入上,但在实际花费里,输出同样可能很贵。
只要任务允许,你都可以直接要求:
- 直接给结论
- 不要套话
- 用列表,不要长篇铺陈
- 只保留必要解释
这不只是省输出 Token,也是在减少后续“再短一点”“再精简一点”的追问轮数。
- 做模型分流
不要让最贵的模型去做最便宜的活。
翻译、润色、摘要、格式整理、校对,这些任务通常不需要一直用最强模型。高成本模型更应该留给复杂推理、跨文档归纳、架构设计和难 bug。
- 关掉不必要的高级能力
Web search、深度思考、复杂工具链,不是默认开得越多越好。
如果任务只是改写、整理、校对、提纲生成或简单问答,它们带来的额外消耗,可能比任务本身还贵。
12 个方法,按“值不值得马上做”排一遍#
| 方法 | 省的是什么 | 怎么做 | 优先级 |
|---|---|---|---|
| 编辑原消息,不要继续补充纠错 | 上下文重复 | 直接改上一条提示词,重新生成 | ⭐⭐⭐ |
| 每 15-20 轮开新对话 | 上下文重复 | 先让 AI 总结进度,带着总结开新线程 | ⭐⭐⭐ |
| 多个相关问题合并成一条消息 | 重复加载上下文 | 一次性交代目标、约束、输出格式 | ⭐⭐⭐ |
| 长文档放进项目知识库 | 重复输入 | 不要在多个会话里反复上传同一份文档 | ⭐⭐⭐ |
| 提前设置记忆和用户偏好 | 重复说背景 | 把身份、语气、固定规则写进记忆 | ⭐⭐⭐ |
| 关掉不必要的 Web search / 深度思考 | 工具调用开销 | 简单任务默认关,需要时再开 | ⭐⭐⭐ |
| 简单任务改用便宜模型 | 单次调用成本 | 校对翻译给小模型,复杂任务给强模型 | ⭐⭐⭐ |
| 用 Caveman 这类 skill 约束输出 | 输出 Token | 让模型少说套话,只保留结论 | ⭐⭐ |
| 浏览器自动化优先用 Playwright CLI | 页面上下文开销 | 快照和截图落文件,按需读取页面信息 | ⭐⭐ |
| 压缩长期提示词和记忆文件 | 输入 Token | 把长规则压成短版本,减少每次读取成本 | ⭐⭐ |
| 用短链式推理替代长推理输出 | 推理输出长度 | 分步思考,但每步只保留最短必要信息 | ⭐⭐ |
| 把重任务分散到一天不同时段 | 配额压力 | 不要把所有大任务堆在同一时间段 | ⭐ |
| 开 Extra Usage 作为兜底 | 任务中断风险 | 设预算上限,额度用尽后按量计费 | ⭐ |
graphify 节约查询量#
前面那些方法,基本都在解决两件事:减少重复、控制长度。
但 graphify 解决的是更底层的问题:你是不是每次都还在从原始文件重新开始。
如果你有下面这些场景:
- 一个陌生代码库,要先理解结构再动手
- 一堆混合资料:代码、Markdown、PDF、截图、论文、笔记
- 同一批文件会被跨会话反复查询
- 项目文档很散,经常要跨文件找关联
那么最贵的往往不是“问一句话”,而是每次都要重新把原始资料喂进去。
这就是 graphify ↗ 的价值所在。它先把资料目录做成知识图谱,再让你基于图谱查询,而不是一次次回到原始文件。
graphify 是什么#
一句话:把任意文件夹里的代码、Markdown、PDF、截图等内容喂进去,输出一张可查询的知识图谱,同时生成可交互 HTML、graph.json 和图谱报告。
它最重要的三个点是:
- 图谱是持久化的。 关系会落到
graph.json里,跨会话保留,不必每次重新读原始文件。 - 溯源是清楚的。 每条边会标成
EXTRACTED、INFERRED或AMBIGUOUS,你能分清哪些是直接提取,哪些是推断。 - 它能发现跨文档关系。 很多连接不是你主动想到去问的,但图谱会帮你连出来。
使用方法#
先安装:
pip install graphifyy && graphify install然后在 Claude Code 里运行:
/graphify .如果你只想分析某个目录,也可以:
/graphify ./raw除了基础跑图,它还有几种很实用的用法:
/graphify ./raw --mode deep
/graphify ./raw --update
/graphify add https://arxiv.org/abs/1706.03762
/graphify query "what connects attention to the optimizer?"
/graphify path "DigestAuth" "Response"
/graphify explain "SwinTransformer"这些命令分别对应几类典型需求:
--mode deep:更激进地抽取推断关系--update:只处理改过的文件,避免整库重跑add:直接把外部资料抓进图谱query:直接查关系path:看两个概念之间怎么连起来explain:理解某个节点在整张图里的位置
运行后,它通常会产出一个 graphify-out/ 目录,里面包括:
graph.html:可交互图谱graph.json:持久化图谱数据GRAPH_REPORT.md:关键节点、意外连接和建议问题cache/:缓存
它带来的增益#
graphify 和 Caveman 的方向完全不同。
Caveman 解决的是“回答太长”。
graphify 解决的是“每次都要重新读整批资料”。
它对使用者的主要增益有四个:
1. 降低重复输入成本#
这是最核心的收益。
当一批资料已经被做成图谱,后续很多问题就可以基于图谱查询,而不是再次把原文喂进去。你的查询成本会逐步从“读文件”转向“查关系”。
2. 提高跨文档理解效率#
直接读原始文件时,人很容易只看到局部。图谱的优势是把代码、文档、图片、论文之间的关系放在一张图里,适合快速建立整体理解。
3. 支持跨会话复用#
很多省 Token 技巧只在单次对话里有效。graphify 的不同点在于,它把结构留下来了。你这次建完图,下次还可以继续查。
4. 更适合大语料和长期项目#
小项目里,几个文件直接读就够了。
但当资料越多、结构越散、问题越反复,图谱的复利就会越来越明显。
我的博客项目实测#
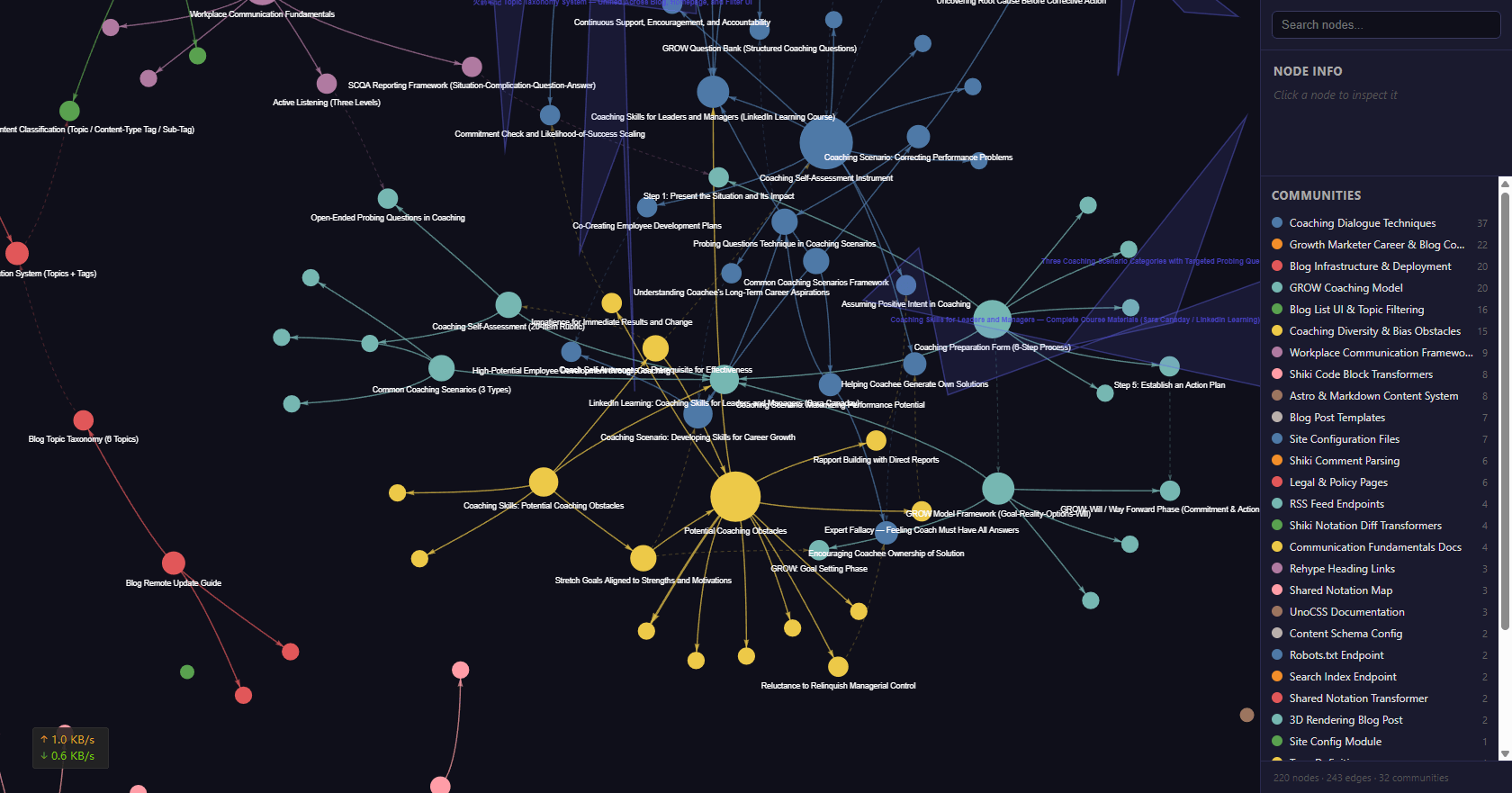
我对这个博客项目(src/ + docs/ 目录,47 个文件)跑过一次 graphify:
| 指标 | 数据 |
|---|---|
| 语料规模 | 96.3 万词,含 18 个 TypeScript 文件、29 篇 Markdown、0 份 PDF |
| 图谱规模 | 220 个节点,243 条边,22 个社区 |
| 每次查询平均消耗 | ~2,096 tokens |
| 压缩比 | 613x |
也就是说,以前直接喂原始文件回答一个问题,大概要花约 128 万 tokens;现在走图谱,同样的问题只需要约 2,096 tokens。
这个收益在小项目上不明显,但在“资料多、查询反复、会话长期”的场景里,会非常夸张。
什么时候值得上 graphify#
适合:
- 陌生代码库
- 大量文档或混合资料
- 跨会话反复查询
- 有长期积累的
raw/文件夹
不太适合:
- 文件少于 10 个
- 内容每次都会整体替换
- 只是一次性临时问答
Playwright CLI 节约浏览器自动化 Token#
如果你的场景不是“查资料”,而是让 AI 自己去看网页、点按钮、填表单、检查报错,那么还有一种常被忽略的开销:浏览器操作本身,也会吃掉大量上下文。
很多人以前用的是浏览器 MCP。它当然能用,但问题也很直接:每次操作都容易把整页结构重新塞回上下文。打开一次页面、点一次按钮、再看一次报错,Token 就会一轮轮涨上去。
Playwright CLI 的思路更轻。它把页面快照和截图保存成文件,模型只在需要时去读,而不是每一步都被迫重新“看完整个页面”。对前端开发、表单测试、线上巡检这种会频繁操作网页的任务来说,这个差别很实际。
为什么它更省#
- 页面结构通过
snapshot落到文件,不默认塞进上下文 - 截图保存为 PNG,按需读取,不用每次把图片内容带进对话
- CLI 本身比一整套 MCP 工具定义更轻,初始化成本更低
- 长流程任务更不容易因为页面反复回传而快速退化
按补充资料里引用的测试数据,同一个任务大约可以从 ~114,000 tokens 降到 ~27,000 tokens,差不多是4倍的差距。对“让 AI 自己看网页再继续改”的工作流,这类节省是很有体感的。
使用方法#
先安装:
npm install -g @playwright/cli@latest
playwright-cli install-browser
playwright-cli install --skills装好之后,常见操作大概是这样:
playwright-cli open https://localhost:3000 --headed
playwright-cli snapshot
playwright-cli click e21
playwright-cli fill e15 "hello"
playwright-cli screenshot这里的 e21、e15 是页面元素编号。也就是说,AI 不必反复写 CSS 选择器或手动找 DOM 路径,先看快照,再按编号操作就行。
它适合什么场景#
- 改完样式后,让 AI 自己打开页面、自检、自截图
- 跑登录、注册、搜索这类表单流程
- 检查线上页面能不能正常加载、导航能不能点、控制台有没有报错
它不一定适合所有人。
如果你几乎不做网页交互,也不需要 AI 代你跑浏览器,那这部分开销本来就不存在;但只要你已经进入“AI 要自己看页面”的阶段,Playwright CLI 往往比 MCP 式操作更省。
Caveman 节省输出量#
如果你遇到的问题是:模型并没有答错,但总是太啰嗦、太爱铺垫、太喜欢说漂亮话,那 Caveman 这种 skill 是值得试的。
它的本质不是“让模型变聪明”,而是强约束输出风格。你可以把它理解成一个“把答案压到只剩骨架”的输出模式。
使用方法#
官方仓库目前给出的几种安装方式如下。
通用安装#
npx skills add JuliusBrussee/caveman给指定 Agent 安装#
npx skills add JuliusBrussee/caveman -a cursor
npx skills add JuliusBrussee/caveman -a github-copilot
npx skills add JuliusBrussee/caveman -a cline
npx skills add JuliusBrussee/caveman -a windsurf
npx skills add JuliusBrussee/caveman -a codexClaude Code 插件方式#
claude plugin marketplace add JuliusBrussee/caveman
claude plugin install caveman@cavemanCodex 的本地安装思路#
根据 README,Codex 用户可以这样装:
- 克隆
JuliusBrussee/caveman仓库。 - 在仓库里打开 Codex。
- 运行
/plugins。 - 搜索
Caveman。 - 安装插件。
仓库还特别提到,Windows 上如果走本地 marketplace 路径,最好先执行 git config core.symlinks true,并确保系统已开启开发者模式或管理员权限,否则符号链接可能出问题。
参考链接: https://developers.openai.com/codex/plugins/build?install-scope=workspace ↗
它带来的增益#
Caveman 最直接的收益,不是减少输入,而是减少输出。
- 回答更短,废话更少
- 结论更靠前,不用在段落里捞重点
- 在高频问答、代码 review、命令式协作里更省心
- 当你本来就知道背景,只想快速拿结果时,体验会明显变好
换句话说,它适合的是“模型已经能做对,但说得太多”的场景。
它不太适合的情况也很明显:
- 你是初学者,需要完整解释
- 任务本身依赖细致背景铺垫
- 你需要面对外部读者生成成稿,而不是给自己看结论
所以 Caveman 更像一个“压缩输出”的阀门,不是万能省 Token 工具。

最后怎么选:先用哪一种?#
如果你现在的问题是:
- AI 改完前端后看不到效果
- 需要频繁点页面、填表单、截图、看报错
- 浏览器自动化一开,Token 掉得特别快
优先试 Playwright CLI。
如果你现在的问题是:
- 模型太啰嗦
- 结论埋得太深
- 你已经知道背景,只想更快拿答案
优先试 Caveman。
如果你现在的问题是:
- 项目资料太多
- 同一批文件反复查询
- 每次都在重新贴原文
优先试 graphify。
如果你还没到需要上工具的阶段,那就先把最基础的 4 件事做好:
- 少补丁式追问,多编辑原消息
- 少堆长上下文,多做阶段总结
- 少让模型写长文,多限制输出长度
- 少让重模型做轻任务,多做模型分流
FAQ:最容易被误解的几个问题#
文言文一定更省 Token 吗?#
不一定。
Token 不是按字数机械收费,而是按分词和语义切分计算。字更少,不代表一定更省。
生僻字和“压缩表达”为什么有时反而更贵?#
因为越少见的表达,越可能被切成更多片段。真正有效的方向,不是把话说得更怪,而是让信息更清晰、上下文更少重复、输出更少废话。
什么时候应该开新对话?#
当你发现当前对话已经累积了很多历史信息,而当前任务只依赖其中一小部分时,就该开新线程。最稳的做法是:先让 AI 总结当前阶段,再带着总结开新对话。
什么时候应该关闭 Web search 或高强度思考?#
当任务只是校对、改写、整理、简单问答时,通常都可以先关掉。只有在你真的需要最新信息、外部来源或复杂推理时,再把这些能力打开。
最终结论#
原文里最有价值的,不是“洞穴人语言”这个梗,而是背后的同一个原则:
减少无意义的上下文重复,减少无意义的输出冗余,减少不必要的高成本能力调用。
顺着这个原则往下做,工具和方法就会自然分层:
- 日常对话里,先优化上下文和输出
- 前端页面要反复看、点、测时,用
Playwright CLI - 输出太啰嗦时,用
Caveman - 资料太多、查询太重复时,用
graphify
真正值钱的,不是“某个神奇技巧”,而是你开始用更低成本的方式,让模型只处理真正值得它处理的部分。